
By Edwin Weijdema, Sales Engineer, Nexenta
In this second post of the multi-post Three Dimensions of Storage Sizing & Design we will dive deeper in the dimension: Use and specifically the application Workloads part. By developing an understanding of the different kind of workloads and their characteristics will enable you to look at your different workloads and determine what impact that will have on the design and sizing. Knowing, understanding and classifying which applications will run as a workload interacting with the storage, gives you an important puzzle piece.
Knowing workloads
Applications have been created to support us and automate processes to work efficient and swift with the available data. Today we use, protect and manage an overwhelming amount of data that is being transformed into information through all kinds of applications. Most of these applications also interact with our storage systems. Overlooking the divers application landscape and how they interact with the storage systems(s), we can organize them in several categories where the most common ones are:
Transactional Enterprise Applications – are used to work with data that triggers an internal or external event or transaction that takes place as an organization conducts its business. A lot of people also like to simplify this by calling it the database backend. For example an online ordering system, where orders are being entered through a web interface, and than stored in a database. (e.g. SQL, Exchange, CRM, e-Business, Oracle, SAP, PostgreSQL, Sharepoint, Call Centre Systems, etc.)
Virtualization – translates the physical hardware and operating system the application runs on and creates a virtual machine in the form of a few files gathered in a folder. Most organizations are using Virtual Machines and/or Virtual Desktops to run their applications. This is a great way to consolidate infrastructures onto a few physical machines, reducing costs and making infrastructures more agile and flexible. By consolidating the different applications, servers and desktops onto a virtual environment also consolidates and changes the I/O data path to and from the storage. (e.g. VMware vSphere, VMware Horizon, Microsoft Hyper-V, Citrix Xenserver, Cloudstack, Openstack, etc.)
Generic Enterprise Fileservers – stores small to large files from all kinds of applications. Often you will see documents, pictures, media files and such. Any sort of file saved by applications and usually accessed over SMB/CIFS/NFS protocol.
Back-up & Archive – back-up and archiving systems have two distinct and complementary functions within an enterprise: backup for high-speed copy and restore to minimize the impact of failures, human error or disaster; and archiving to effectively manage data for retention and long-term access and retrieval. (e.g. Veeam, Commvault, Veritas, etc.)

Understanding workloads
Understanding workloads and specifically the Disk I/O pattern of enterprise applications helps tremendous with designing and sizing your storage solution(s). So you can make sure that your users, with their applications, are being optimal supported by the storage system. Vendors of enterprise application software often do not inform users about their workload characteristics. This is because the same application may generate different workload patterns depending upon the user’s configuration, or they simply do not know!
Workload characteristics
In this post we will just do a high level overview of the different workload characteristics and the relationship between them. In the next post we will dive deeper into the technical background of speed, throughput and response.
Workloads have several characteristics that define the workload type:
- Speed – measured in IOPS (Input/Output Per Second), defines the IOs per second. Read and/or Write IOs can be of different patterns (for example, sequential and random). The higher the IOPS the better the performance.
- Throughput – measured in MB/s, defines data transfer rate also often called bandwidth. The higher the throughput, the more data that can be processed per second.
- Response – measured in time like ns/us/ms latency, defines the amount of time the IO needs to complete. The lower the latency the faster a system/application/data responds, the more fluid it looks to the user. There are many latency measurements that can be taken throughout the whole data path.
Random versus Sequential access pattern
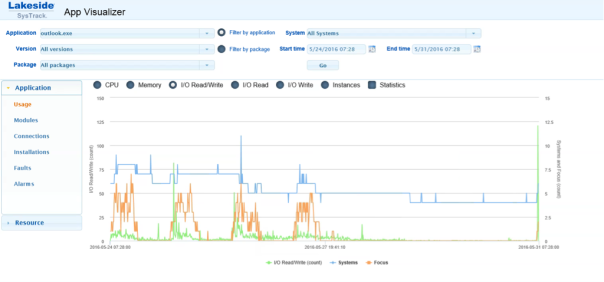
While looking at your applications and how they access their data gives you a good indication if the access pattern is random or sequential. Sequential access means all data blocks will be accessed/written after each other so 1 > 2 > 3 > 4 > 5 where Random access can mean 5 > 1 > 3 > 2 > 4. Accessing data sequentially is much faster than accessing it randomly, because of the way disk hardware works. With spinning disk the seek operation takes the most time in the whole I/O process. The disk head needs to position itself at the correct disk platter to access the requested data. Randomly reading data takes a larger number of seek operations than sequential reading, meaning that the throughput with random will be much lower than sequential. The same applies to random writing. Examining the used workloads might be useful for designing and sizing the storage system. You could use for instance Lakeside Systrack software to give a good indication in the way the workload runs and interacts with the storage.
I/O Size in the mix
The amount of throughput we can achieve is dependent on the pattern to be random or sequential and the I/O size that is being issued. For a workload with an I/O size of 4k block-size you can calculate the throughput by multiplying the number of IOPS times the I/O size.
Throughput in MB/sec = (IOPS x I/O size) / 1024
So 10.000 IOPS with an 4k block-size will be (10.000 x 4k)/1024 = 39.06 MB/sec throughput you can achieve. The whole data path should be addressed too get a clear insight and more accurate number though!
Looking at a random workload you will see that latency will start to kick in which will reduce the number of IOPS that can be achieved by the storage so random IOPS can reduce the amount of throughput significantly. A SSD produces much more IOPS and throughput against very low latency, because it does not contain moving parts. So why not go all flash than? Its all about knowing and understanding your workloads and deciphering if you need that amount of power against the cost associated with it. Balancing costs against requirements is the best way to go forward.
Classifying workloads
Lets start classifying the different workloads we identified, with the different characteristics that are important for storage. Looking at the four most common workloads:
Transactional Enterprise Applications
Transactional Enterprise Applications often are backed by a database where response is key. Looking at an Oracle database you will see that by decreasing latency will reduce the Wait states and by decreasing the Wait states the usage of CPU capacity will be reduced. If you are running virtualized Oracle database you might want to consider reducing latency and free up CPU cycles so you can run more database on that same CPU, therefore reducing your Oracle licensing cost.
Transactional Enterprise Applications tend to have a high amount of small random read I/O and a desire for fast response (low latency).
Virtualization
Virtualization is a unique workload because it consolidates several different application workloads with their corresponding characteristics on the hypervisor. So you will have several applications doing for instance random 4k, 8k and 16k blocks within the VM but the hypervisor absorbs those in memory and transforms them into 1MB or 2MB blocks which it sends and requests from the storage. VMware ESXi with VMFS5 uses 1MB unified blocks, while Microsoft Hyper-V uses 2MB blocks.
Virtualization and its consolidation also bring some storage benefit because not every application workload is going to peak at the same time. So rather than over provision it is better to look at the total picture.
Virtualization workloads tend to be fully random with a desire for speed (IOPS).
Generic Enterprise Fileserver
Generally a File Share is used by lots of users in an organization and different applications storing their data on those file shares. Users will open a file and work in/with it for some time before saving it to the file share again. So throughput to get and save the file for the user is often most important. But depending on the applications storing files it can also be that speed is required in terms of IOPS.
Generic Enterprise Fileserver workloads tend to be often sequential, but can be random with a desire for throughput (MB/s).
Back-up & Archive
Back-up & Archive workloads look like a workload that would benefit the most by maximizing throughput. This is really depending on how you use the application and which options you configure.
Lets look at for instance Veeam, the performance of many Veeam Backup & Replication functions, such as Reverse Incremental, Synthetic Full, SureBackup and Instant Restore are most impact by the ability of the storage array to deliver random IOPS.
Veeam Backup & Replication offers two primary modes for storing backups to disk, Forward and Reverse incremental. Due to the differences in how these modes write backups to disk they have very different storage I/O profiles.
Forward Incremental backups offer the advantage that they perform only sequential writes to the target repository meaning that performance is significantly higher than reverse incremental backups. However, this backup mode does come with costs, primarily in the requirement to schedule periodic full backups. These backups will take additional time to create and, based on the method, addition space on the target repository.
There are three options for creating new full backups:
Synthetic Full — this method uses the most recent full backup, and any incremental backups created since then and builds a new full backup using this data. This requires space for a new full backup, and random I/O on the target repository and can take a long time to process.
Synthetic Full w/Transform — this method uses the most recent full backup, and any incremental backups created since then and builds a new full backup using this data, while converting the incremental backups to reverse incremental files. This requires only a small amount of additional space on the target repository, but usage a large amount of random I/O and can take a very long time to process
Active Full — this method simply runs a new full backup by reading all data from the source VMs. This requires I/O on the source storage, enough space to store a new full backup and sequential write I/O on the target repository.
Back-up & Archive workloads tend to be often sequential, but can be fully random with a high desire for throughput (MB/s) and speed (IOPS).
Summary
Interestingly, workload characterization is not only useful for sizing and designing storage systems but also useful for application developers to help them optimize their I/O routines or to document best practices based on such analysis. In the next part of Three Dimensions of Storage Sizing & Design we will dive deeper into workload characteristics speed (IOPS), throughput (MB/s) and Response (ms).